
728x90
그래프를 탐색하는 방법에는 크게 두 가지가 있다.
- 깊이 우선 탐색(Depth First Search, DFS)
- 저번에 봤듯이 Stack 또는 재귀의 단계를 활용하여 구현
- 너비 우선 탐색(Breadth First Search, BFS)
- 탐색 시작점의 인접한 정점들을 먼저 모두 차례로 방문한 후, 방문헀던 정점을 시작점으로 하여 다시 인접한 정점들을 차례로 방문하는 방식
- 인접한 정점들에 대해 탐색을 한 후, 차례로 다시 너비우선탐색을 진행해야 하므로 선입선출 형태의 자료구조인 큐를 활용
순서

def BFS(G, v): # 그래프 G, 탐색 시작점 v
visited = [0]*(n+1) # n: 정점의 개수
queue = [] # 큐 생성
queue.append(v) # 시작점 v를 큐에 삽입
while queue: # 큐가 비어있지 않은 경우
t = queue.pop(0) # 큐의 첫번째 원소 반환
if not visited[t]: # 방문되지 않은 곳이라면
visited[t] = True # 방문한 것으로 표시
visit(t)
for i in G[T]: # t와 연결된 모든 정점에 대해
if not visited[i]: # 방문되지 않은 곳이라면
queue.append(i) # 큐에 넣기
구현 예제
1. 초기 상태
- Visited 배열 초기화
- Q 생성
- 시작점 enqueue
2. A점부터 시작
- dequeue: A
- A 방문 표시
- A 인접점 enqueue
3. 탐색 진행
- dequeue: B
- B 방문한 것으로 표시
- B의 인접점 enqueue
4. 탐색진행
- 3번을 계속 반복한다.
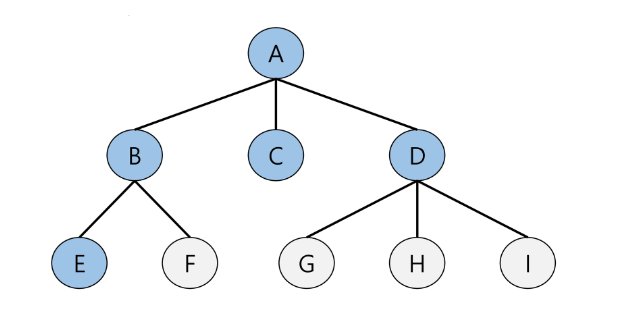
5. Q가 빈다면 탐색종료

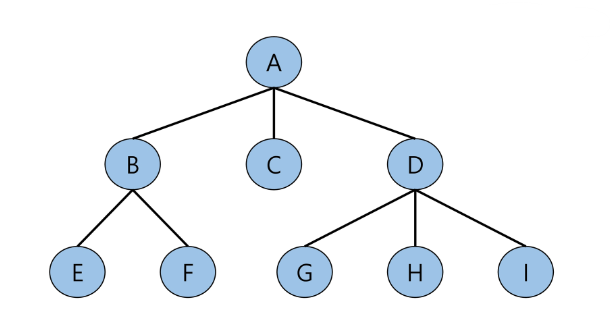
이렇게 BFS의 과정에 대해서 살펴봤다.
아직은 나도 이해가 잘 되지 않지만 BFS와 DFS의 차이점을 실습해보며 이해해보자!!
728x90
'ALGORITHM > 알고리즘 알아보기' 카테고리의 다른 글
| [알고리즘] 정렬1 - 버블, 카운팅, 선택 정렬 (0) | 2022.09.09 |
|---|---|
| [Algorithm] 최장 증가 수열 (LIS) (0) | 2022.09.07 |
| [알고리즘] 분할 정복 (0) | 2022.08.22 |
| [알고리즘] 백트래킹(Backtracking) (0) | 2022.08.22 |
| [알고리즘] 후위 표기법 - 계산기 (0) | 2022.08.22 |