
728x90
앞선 글들에서는 조회 및 필터링을 이용한 중복 제거, 조건 설정 등 쿼리를 제어하는 방법에 대해 알아보았다.
이번 글에서는 특정 그룹으로 묶어주는 Grouping과 데이터를 삽입, 수정, 삭제하는 법에 대해 알아보자
목차
- Grouping data
- Insert
- Update
- Delete
1. GROUP BY clause
SELECT column_1, aggregate_function(column_2)
FROM table_name
GROUP BY column_1, column_2;- Make a set of summary rows from a set of rows
- 특정 그룹으로 묶인 결과를 생성
- 선택된 컬럼 값을 기준으로 데이터(행)들의 공통 값을 묶어서 결과로 나타냄
- SELECT 문에서 선택적으로 사용 가능한 절
- SELECT 문의 FROM 절 뒤에 작성
- WHERE 절이 포함된 경우 WHERE 절 뒤에 작성해야 함
- 각 그룹에 대해 MIN, MAX, SUM, COUNT 또는 AVG와 같은 집계 함수(aggregate funcion)를 적용하여 각 그룹에 대한 추가적인 정보를 제공할 수 있음
Aggregate function
- "집계 함수"
- 값 집합의 최대값, 최솟값, 평균, 합계 및 개수를 계산
- 값 집합에 대한 계산을 수행하고 단일 값을 반환
- 여러 행으로부터 하나의 결과 값을 반환하는 함수
- SELECT 문의 GROUP BY 절과 함께 종종 사용됨
- 제공하는 함수 목록
- AVG(), COUNT(), MAX(), MIN(), SUM()
- AVG(), MAX(), MIN(), SUM()는 숫자를 기준으로 계산이 되어져야 하기 때문에 반드시 컬럼의 타입이 INTEGER
users 테이블의 전체 행 수 조회하기
SELECT COUNT(*) FROM users;
나이가 30살 이상인 사람들의 평균 나이 조회하기
SELECT AVG(age) FROM users WHERE age>= 30;
각 지역별로 몇 명씩 살고 있는지 조회하기
- country 컬럼으로 그룹화
SELECT country FROM users GROUP BY country;
- 몇 명씩 사는지 계산하기 위해 Aggregation Function의 COUNT를 사용
- 각 지역별로 그룹이 나뉘어졌기 때문에 COUNT(*)는 지역별 데이터 개수를 세게 된다.
SELECT country, COUNT(*) FROM users GROUP BY country;
※ COUNT 참고사항
- 이전 쿼리에서 COUNT(), COUNT(age), COUNT(last_name) 등 어떤 컬럼을 넣어도 결과는 같음
- 현재 쿼리에서는 그룹화된 country를 기준으로 카운트 하는 것이기 때문에 어떤 컬럼을 카운트해도 전체 개수는 동일
각 성씨가 몇 명씩 있는지 조회
SELECT last_name, COUNT(*) FROM users
GROUP BY last_name;
- AS 키워드를 사용해 컬럼명을 임시로 변경하여 조회 가능
SELECT last_name, COUNT(*) AS number_of_name
FROM users GROUP BY last_name;
Changing Data를 들어가기 전 편의를 위해서 새 테이블 생성해주자.
CREATE TABLE classmates(
name TEXT NOT NULL,
age INTEGER NOT NULL,
address TEXT NOT NULL
);
2. INSERT statement
INSERT INTO table_name (column1, column2, ...)
VALUES (value1, value2, ...);
- "Insert new rows into a table"
- 새 행을 테이블에 삽입
- 문법 규칙
- 먼저 INSERT INTO 키워드 뒤에 데이터를 삽입할 테이블의 이름을 지정
- 테이블 이름 뒤에 쉼표로 구분된 컬럼 목록을 추가
- 컬럼 목록은 선택 사항이지만 컬럼 목록을 포함하는 것이 권장됨
- VALUES 키워드 뒤에 쉼표로 구분된 값 목록을 추가
- 만약 컬럼 목록을 생략하는 경우 값 목록의 모든 컬럼에 대한 값을 지정해야 함
- 값 목록의 값 개수는 컬럼 목록의 컬럼 개수와 같아야 함
단일 행 삽입하기
-- 1
INSERT INTO classmates (name, age, address)
VALUES ('홍길동, 23, '서울');
--2
INSERT INTO classmates
VALUES ('홍길동', 23, '서울');
여러 행 삽입하기
INSERT INTO classmates
VALUES
('김철수', 30, '경기'),
('이영미', 31, '강원'),
('박진성', 26, '전라'),
('최지수', 12, '충청'),
('정요한', 28, '경상');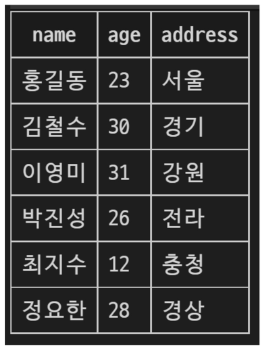
3. UPDATE statement
UPDATE table_name
SET column_1 = new_value_1,
column_2 = new_value_2
WHERE
search_condition;
- Update existing rows in a table
- 테이블에 있는 기존 행의 데이터를 업데이트한다.
- 문법 규칙
- UPDATE 절 이후에 업데이트할 테이블을 지정
- SET 절에서 테이블의 각 컬럼에 대해 새 값을 설정
- WHERE 절의 조건을 사용하여 업데이트할 행을 지정
- WHERE 절은 선택 사항이며, 생략하면 UPDATE 문은 테이블의 모든 행에 있는 데이터를 업데이트 함
- 선택적으로 ORDER BY 및 LIMIT 절을 사용하여 업데이트할 행 수를 지정할 수도 있음
2번 데이터의 이름을 '김철수한무두루미', 주소를 '제주도'로 수정하기
UPDATE classmates
SET name='김철수한무두루미',
address = '제주도'
WHERE rowid = 2;
4. DELETE statement
DELETE FROM table_name
WHERE search_condition;
- Delete rows from a table
- 테이블에서 행을 제거
- 테이블의 한 행, 여러 행 및 모든 행을 삭제할 수 있음
- 문법 규칙
- DELETE FROM 키워드 뒤에 행을 제거하려는 테이블의 이름을 지정
- WHERE 절에 검색 조건을 추가하여 제거할 행을 식별
- WHERE 절은 선택 사항이며, 생략하면 DELETE 문은 테이블의 모든 행을 삭제
- 선택적으로 ORDER BY 및 LIMIT 절을 사용하여 삭제할 행 수를 지정할 수도 있음
5번 데이터 삭제하기 및 삭제된 것 확인
DELETE FROM classmates WHERE rowid = 5;SELECT rowid, * FROM classmates;
이름에 '영'이 포함되는 데이터 삭제하기
DELETE FROM classmates WHERE name LIKE '%영%';
테이블의 모든 데이터 삭제하기
DELETE FROM classmates;
728x90
'CS > Database with SQLite' 카테고리의 다른 글
| [DB] M:N (ManyToManyField) (0) | 2022.10.13 |
|---|---|
| [DB] N:1 realationship (0) | 2022.10.06 |
| [DB] DML2 - Filtering data (1) | 2022.10.05 |
| [DB] DML1 - simple query, Sorting rows (0) | 2022.10.05 |
| [DB] DDL2 - ALTER, DROP TABLE (0) | 2022.10.05 |